Paper|sentence_ordering_and_coherence_modeling
摘要
如何理解文本的连贯性和句子间的内在结构联系,对于多文本摘要、QA等NLP问题来说十分重要。这篇文章基于set-to-sequence框架,提出了一种RNN-base的端到端的深度学习方法,来解决句子的排序和连贯性问题。
问题
- 给一个文档和它打乱的句子集合, 模型对句子进行排序。
- 给一个文档和他打乱的句子集合, 模型选取句子作为文档的摘要。这篇文章选取的是科学文章,它的摘要比较规范。
模型
模型模仿了人类解决这个问题的思维,即先读取句子理解它们的意思,排序时再一个一个选择句子。主要分为read, process 和write三个部分。
我们首先来看下模型的框架, 主要由一个 sentence encoder RNN, set encoder RNN和decoder RNN组成。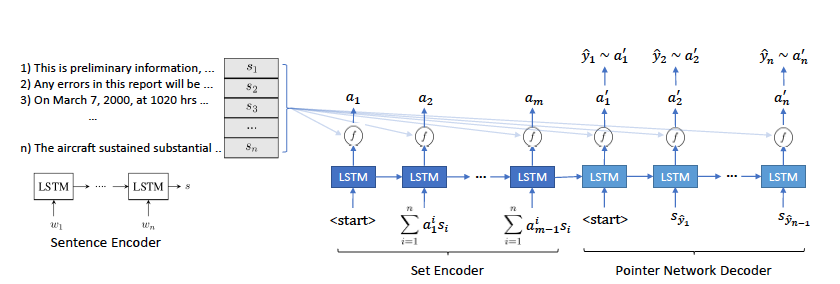
read
sentence encoder RNN没什么好讲的,就是一个LSTM网络把各个句子给向量化,得到${s_1, s_2, …, s_n}$, 它们被用作为sentence memeory
process
就是图中的set encoder部分。LSTM网络每一步的输入是前一步的hidden state与memory进行attention得到。set encoder会执行m步,称为read cycles, 注意到这个encoder的结果与${s_1, s_2, …, s_n}$的顺序是不相干的。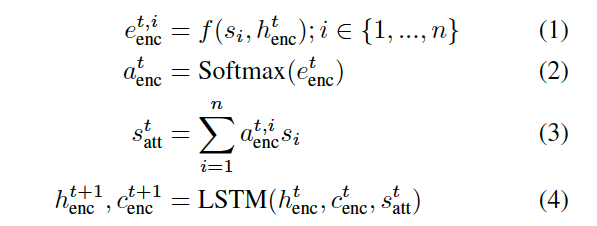
write
decoder是一个pointer network, 在训练时,正确顺序的句子$(s_{o_1}, s_{o_2},…,s_{o_n}) = (x^1, x^2,…,x^n)$ 作为LSTM的输入。预测时前一步的输出$\hat x^{t-1}$作为当前的输入。这里$e^{t,i}_{dec}$ 代表的是在位置$t$,$s_i$作为正确句子的概率。$f$是score函数,可以选择一层feed-forward网络等。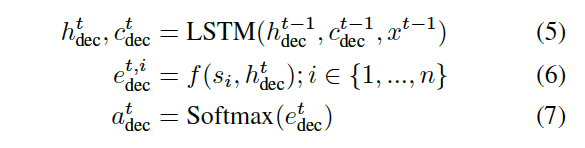
contrastive sentences
为了增加鲁棒性,加入一些随机句子。
coherence modeling and training objective
对于一个结果$(s_{p1}, s_{p2},…,s_{pk}$, coherence score的定义如下: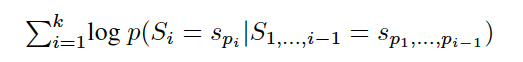
故最大似然的目标函数是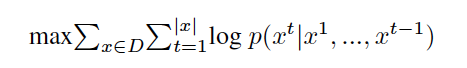
实验和扩展
order descrimination
即给定一个paragraph和它打乱重组的版本集合,选出最相近的,这个问题挑战性并不大。
sentence ordering
给定一堆句子,给它们排序组合成一个段落。主要选取的是科技论文的摘要,因为它们的逻辑结构比较清晰。
sentence ordering and summarization
可以把模型应用于文档摘要,输入文章的句子,然后按照顺序挑选出句子直到预测出结束符。由于这里不要求输入句子的顺序,故也适用于多文档摘要。可以用事先在ordering task上训练好模型,然后将其用于改善摘要模型。而ordering task可以用大量的未标注语料实现,这点是相当有价值的。
learned sentence representations
训练好的sentence encoder 可以用来做句子的向量表达,提升其它任务的表现。