[读Paper]information-extraction-by-acquiring-external-evidence-with-reinforcement-learning
简介
利用自然语言处理技术从文档中来提取或者补全实体信息是非常有用的,然而也充满挑战。文档可能并不含有直观的信息,如下图,我们想从一个关于枪杀案的新闻中提取出枪手、受害者人数的信息,其中,受害者人数无法直接提取,需要复杂的方法才能够得出。

于是,论文提出了引用外部数据,并利用强化学习框架来解决这个问题。 对原文档构建query,再利用搜索引擎,我们就可以得到多个相关的文档。同样上述的例子,在下图两个新闻文档中,就可以分别都很简单地提取出受害者人数和枪手的名字这两个信息,系统对这些信息进行整合,就可以提取出所有的信息。

模型框架
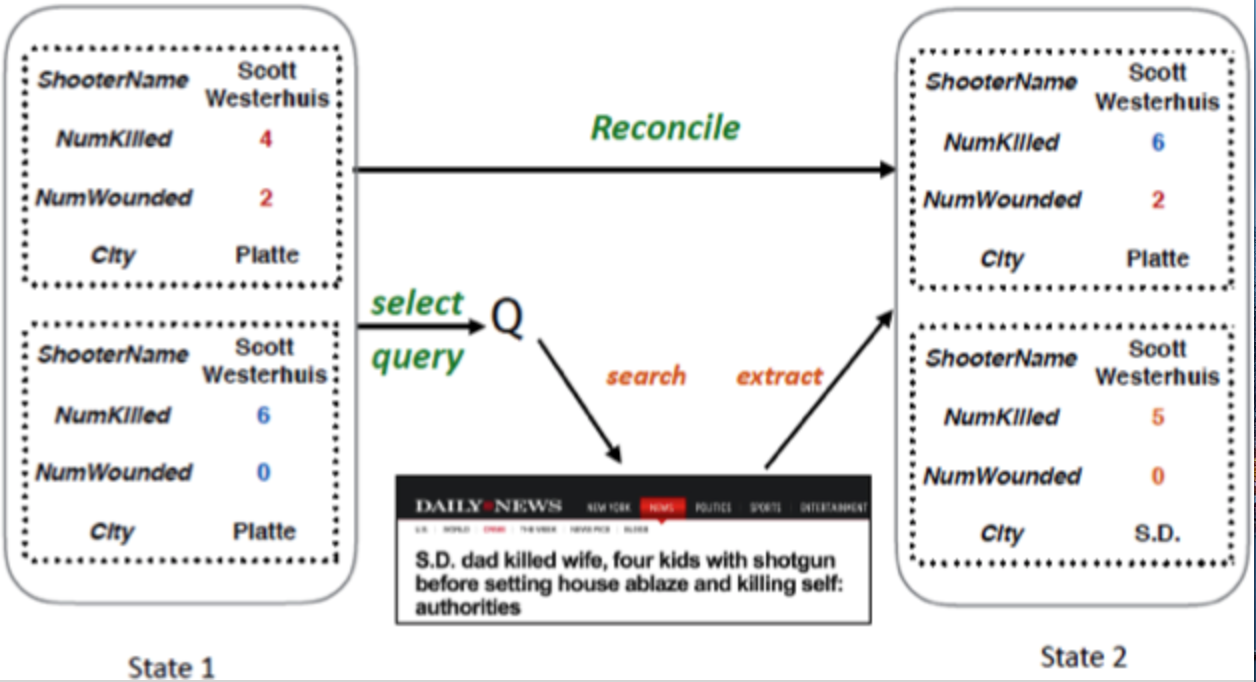
整个信息抽取的过程是一个马尔科夫决策过程(MDP), 每一步,系统将从新文档中提取出的信息($e_new$)和现有的信息($e_cur$)进行整合(Reconcile),并决定如何选取下一个query来进行搜索并提取更多的文章(Q)。
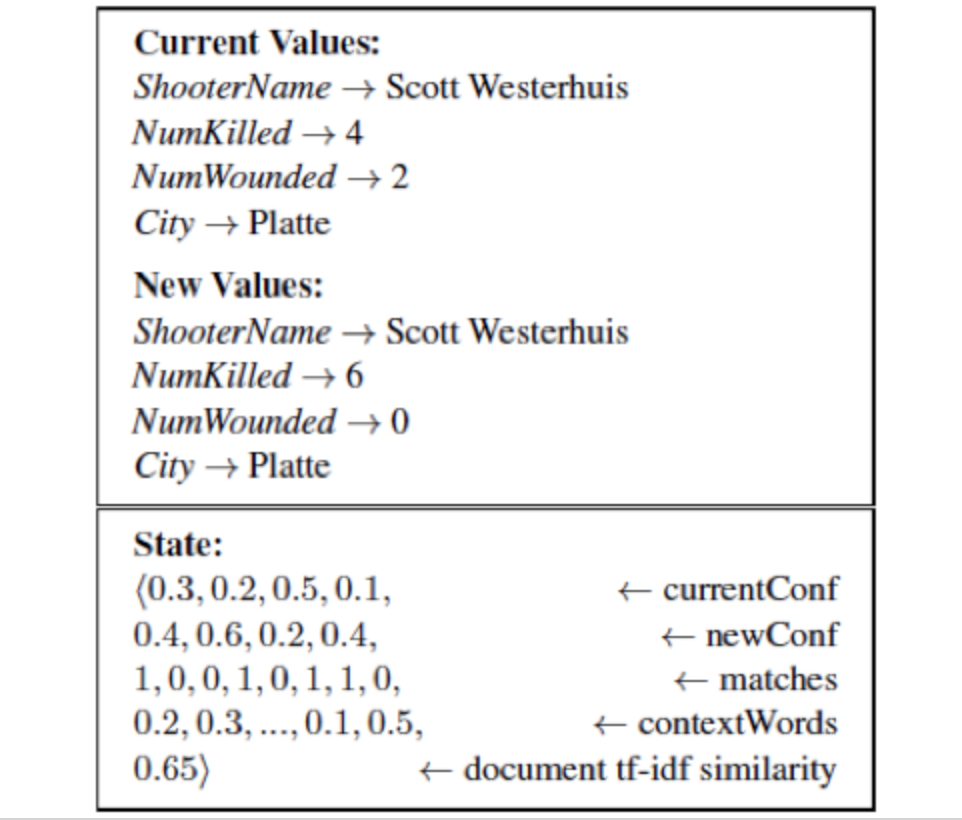
State
其中,对于每一个状态(State)具体情况,包含有:
- $e_cur$的confidence score
- $e_new$的confidence score,* $e_cur$ 和 $e_new$的匹配情况
- contaxt words的unigram/tf-idf值
- 原文档和新文档的tf-idf相似度
Action
一个动作(Action)包含整合与查询新文档,即$a = (d, q)$。 其中,d包括接受部分实体的信息,接受全部实体的信息,拒绝全部实体的信息,停止四种类型的动作。 转移方程$T(s’|s, a$, 根据现在状态S和动作a即可以获得下一个状态。而由现有状态来选择执行什么动作a则是由Agent决定的,这也是使用强化学习训练的地方。
Rewards
对于强化学习,我们还需要定义Rewards函数,用来最大化最后的抽取accuracy并且惩罚过多的query动作。所有实体现有状态的accuracy值和之前状accuracy值之差的和即为reward值。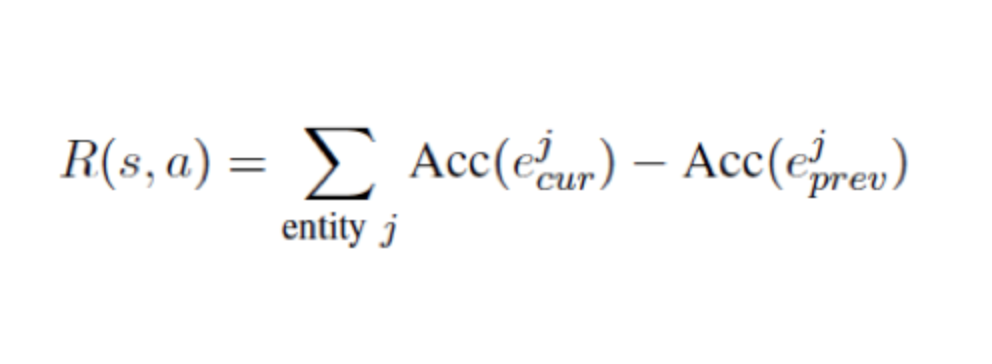
下面是框架的伪代码。其中,13行抽取实体是用的基于最大熵的模型,会在第四节进行介绍。
强化学习
Agent 定义了一个state-action 函数 $Q(s, a)$ 来决定在state s下该执行那个action a。常用Q-learning对最优值进行求解,即迭代地利用得到的rewards对$Q(s, a)$ 进行更新。论文使用了一个深度Q-network($DQN$)对该函数进行学习,下图即为其结构图。
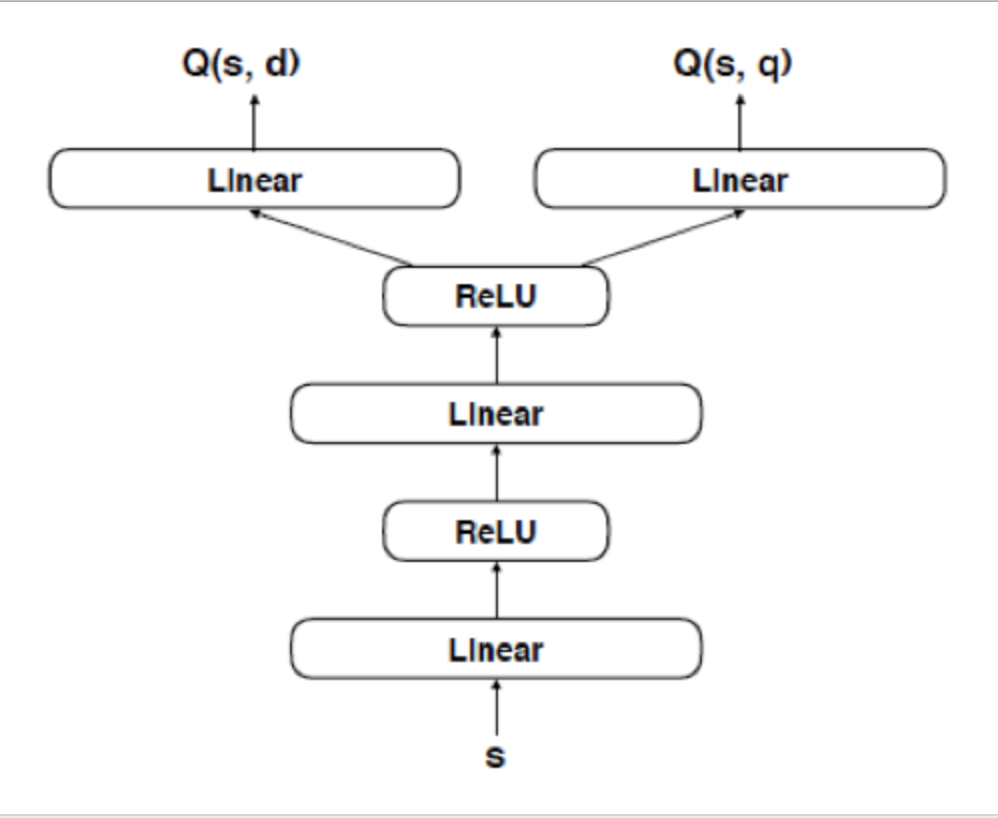
输入为状态向量s, 分别输出整合动作d和查询动作q。参数的学习利用了RMSprop梯度下降法,每次参数迭代旨在减少DQN预测的$Q(s_t,a_t;θ)$ 和有Bellman equation得到的值$r_t+ \gama max_a Q(s_(t+1),a;θ)$的差距。这些都是强化学习里面的概念,不展开讲了。下面是训练Agent的伪代码。

方法对比
论文将强化学习模型与其他方法进行对比。其中,其他模型有:
- 基于CRF和最大熵(Maxent)的分类模型,它们用到的特征如下:
其中,Maxent也在该强化学习模型里用来进行实体抽取。
- 对多个文档的抽取信息进行融合的模型,分别有基于打分的Confidence和基于次数的Majority模型
- 输入和DQN一样的meta-classifer.
论文实验的数据集有两个
- Gun Violence archive,是关于枪杀案的新闻存档,需要提取的信息有:1 枪手的名字, 2 遇害者人数, 3 受伤人数, 发生的城市。
- Foodshield EMA, 包含了食物掺假事件的报道,需要提取的信息有: 1 受影响的食物 2 掺杂物,3 事件发生的地址。
下面是在这两个数据集中增强学习的性能,从 accuracy可以看出它比其他模型都要好。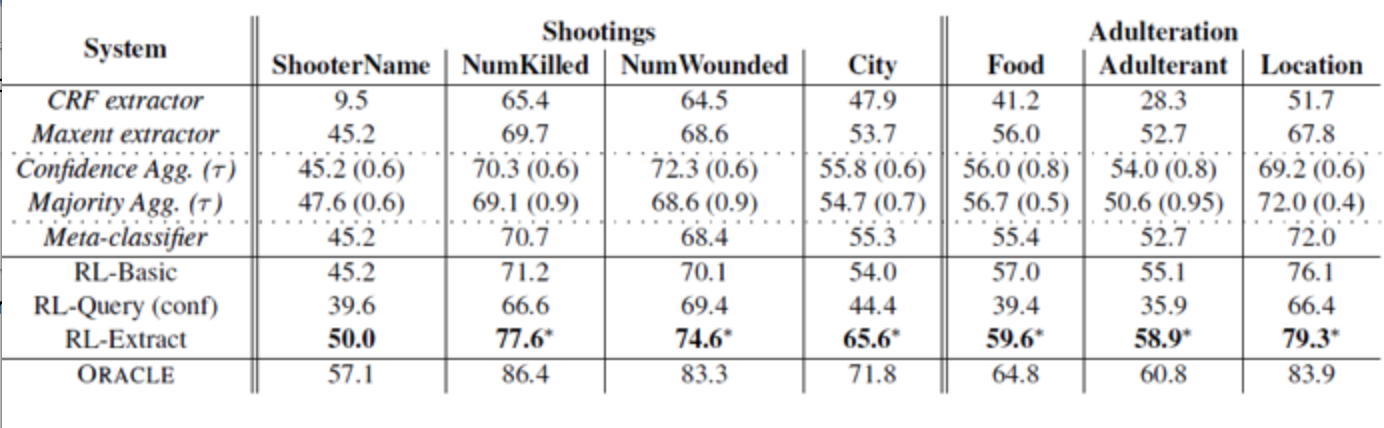
总结
论文将增强学习运用到信息抽取上,利用了不同文本对同一实体信息抽取难度的不同,协调各个源的偏差,有效的提高了抽取的准确度。